Linear Discriminant Analysis in Python
Zhijun / 2022-11-07
Load library
from turtle import shape
import pandas as pd
import numpy as np
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_classification
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
from numpy import mean, unicode_
from numpy import stdLoad the data
oil_data.head()## Number Group Countries 808.5395 ... 1881.3715 1883.301 1885.2305 1887.16
## 0 1 1 Greece 0.103753 ... 0.003744 0.003461 0.002774 0.002253
## 1 1 1 Greece 0.100083 ... 0.004165 0.002345 0.000598 -0.000700
## 2 2 1 Greece 0.098488 ... 0.003454 0.003874 0.003860 0.002053
## 3 2 1 Greece 0.097094 ... 0.004128 0.002877 0.001644 0.000653
## 4 3 1 Greece 0.098733 ... 0.002996 0.001952 0.001568 0.001747
##
## [5 rows x 563 columns]define dataset
X = oil_data.values[:,3:]
y = oil_data.values[:,2]Summarize the dataset
print(X.shape, y.shape)## (120, 560) (120,)LDA model
model = LinearDiscriminantAnalysis()
# define model evaluation method
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv)
# summarize result
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))## Mean Accuracy: 0.975 (0.049)We can see that the model performed a mean accuracy of 97.50%.
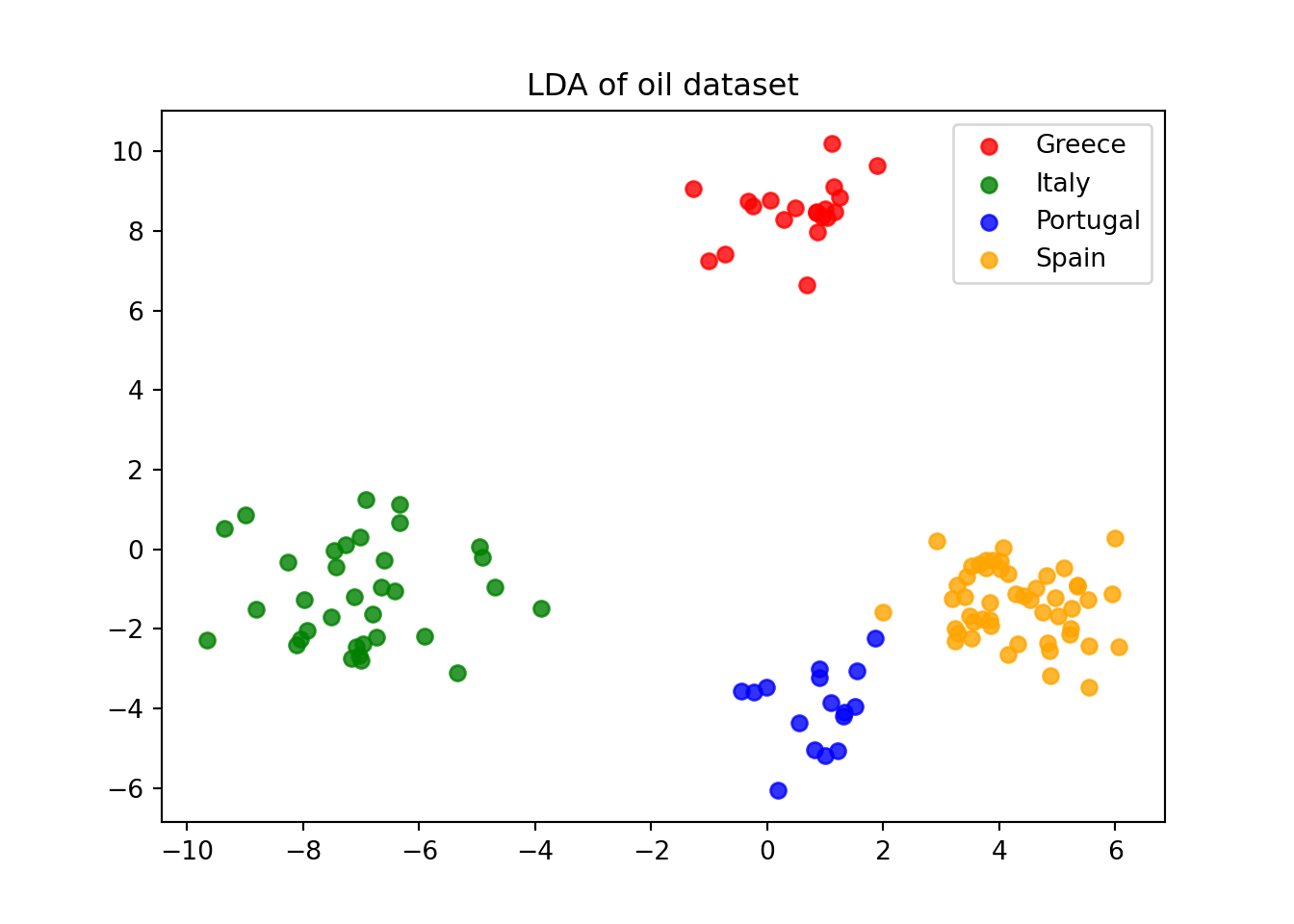
Define data to plot
lda = LinearDiscriminantAnalysis()
data_plot = lda.fit(X, y).transform(X)
target_names = oil_data['Countries'].astype(str).unique()
# Plot
plt.figure()
colors = ['red', 'green', 'blue', 'orange']
lw = 3
for color, i, target_name in zip(colors, ['Greece', 'Italy', 'Portugal', 'Spain'], target_names):
plt.scatter(
data_plot[y == i, 0], data_plot[y == i, 1], alpha=0.8, color=color, label=target_name
)
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.title("LDA of oil dataset")
plt.show()